在數字經濟時代,互聯網數據服務已成為驅動業務增長與創新的核心引擎。構建一套穩定、高效、可擴展的互聯網數據服務業務系統,需要一套系統性的技術架構方法論。這不僅涉及具體的技術選型,更是一個涵蓋業務目標、數據處理全鏈路、系統可靠性、團隊協作與持續演進的綜合性工程。本文將通過實例分析,闡述構建一整套業務系統產品技術架構的核心方法論。
第一階段:架構基石——明確業務目標與技術原則
任何技術架構的起點都必須是業務。以一家提供用戶行為分析服務的公司為例,其核心業務目標可能是“為上千家客戶實時提供精準、多維度的用戶行為洞察”。由此,技術架構的頂層設計原則應運而生:
高并發與實時性: 支持海量客戶同時查詢,數據延遲需控制在秒級。
數據準確性: 確保分析結果的可靠,這是服務的生命線。
多租戶與隔離性: 保證不同客戶數據的完全隔離與安全。
成本可控與彈性伸縮: 隨著客戶和數據量增長,系統能平滑擴展,同時控制基礎設施成本。
明確這些原則,是后續所有技術決策的“北極星”。
第二階段:核心流程拆解——數據流與處理鏈路的架構設計
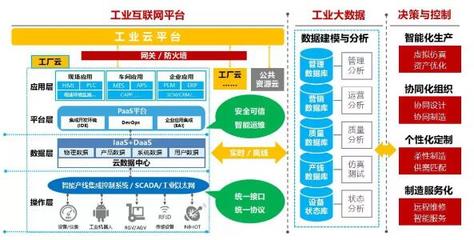
將業務目標映射為具體的數據處理流水線,是架構設計的關鍵。一個典型的數據服務系統通常包含以下核心鏈路:
- 數據采集與接入層: 采用Agent、SDK或日志收集框架(如Flume、Logstash),設計高吞吐、低侵入的數據上報方案。實例中,可采用輕量級SDK實現客戶端事件埋點,通過HTTP或Kafka將數據異步發送至網關。
- 數據處理與計算層: 這是系統的“大腦”。需根據實時和離線場景分層設計:
- 實時流處理: 采用Flink或Spark Streaming,對流入的數據進行實時清洗、過濾、聚合,寫入OLAP數據庫(如ClickHouse、Doris)或實時數倉,支撐秒級查詢。
- 離線批處理: 利用Hadoop、Spark構建數據倉庫,進行復雜的T+1深度分析、模型訓練和數據挖掘,結果存儲于Hive或對象存儲中。
- 數據存儲與查詢層: 根據數據特性和訪問模式選擇合適的存儲引擎。
- 明細數據: 可存入HBase或Cassandra,用于原始數據追溯。
- 聚合分析數據: 使用列式存儲的OLAP引擎(如ClickHouse),提供極速的多維分析查詢能力。
- 元數據與配置: 使用關系型數據庫(如MySQL)或Etcd進行管理。
- 服務與應用層: 構建面向客戶和內部運營的API服務與前端應用。采用微服務架構,將數據查詢、報表生成、權限管理等功能拆分為獨立服務,通過API網關統一暴露。使用緩存(如Redis)提升高頻查詢接口的性能。
第三階段:橫向能力構建——保障系統健壯性與可運維性
一個完整的架構必須包含支撐核心鏈路平穩運行的橫向能力:
- 高可用與容災: 關鍵組件(如Kafka集群、計算引擎、數據庫)需實現多副本和跨可用區部署。設計熔斷、降級、限流策略,確保局部故障不影響整體服務。
- 數據安全與治理: 實施端到端的數據加密(傳輸中與靜止時),嚴格的基于角色的訪問控制(RBAC),以及審計日志。建立數據血緣和質量監控體系。
- 監控與可觀測性: 建立涵蓋基礎設施(CPU、內存)、應用(JVM、GC)、業務(關鍵指標如查詢QPS、延遲、數據延遲)的全鏈路監控,使用Prometheus、Grafana、ELK棧等工具實現日志、指標、追蹤的立體觀測。
- 資源管理與調度: 在容器化(如Kubernetes)環境下部署微服務和計算任務,實現資源的彈性調度與高效利用。
第四階段:持續演進——架構的迭代與團隊協作
技術架構不是一成不變的藍圖,而是一個持續演進的活系統。
- 迭代式開發: 采用敏捷開發模式,優先構建最小可行產品(MVP)架構,快速驗證核心鏈路,再逐步迭代增加實時分析、高級功能模塊。
- 標準化與自動化: 通過基礎設施即代碼(IaC)、CI/CD流水線,實現環境與部署的標準化和自動化,提升交付效率與質量。
- 團隊與知識管理: 架構設計需與團隊組織架構(如康威定律)相適應。建立清晰的技術文檔、架構決策記錄(ADR),保障知識的傳承和架構的一致性。
**
構建互聯網數據服務業務系統的技術架構,是一個從業務目標出發,貫穿數據價值流,并最終回歸業務價值創造的閉環過程。其方法論的核心在于:以終為始的業務驅動、分層解耦的流水線設計、全面覆蓋的支撐體系,以及擁抱變化的演進思維。** 通過這套系統性的方法論,技術團隊能夠構建出不僅滿足當前需求,更能靈活適應未來挑戰的、堅實可靠的數據服務基礎設施。